

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?()
A.建模描述
B.根据内容检索
C.寻找模式和规则
D.预测建模
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
A.建模描述
B.根据内容检索
C.寻找模式和规则
D.预测建模
答案
 更多“建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?()”相关的问题
更多“建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?()”相关的问题
第1题
本题使用GPA2.RAW中的数据。
(i)考虑方程
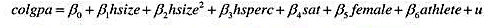
其中,colgpa表示累积的大学GPA,hsize表示高中毕业年级以百人计的规模,hsperc表示在毕业年级中学术排名的百分位,sat表示SAT综合分数,female是一个二值变量,而athlete也是一个运动员取值1的二值变量。你对这个方程中的系数有何预期?哪些你没有把握?
(ii)估计第(i)部分中的方程,并以通常的形式报告结果。估计运动员和非运动员之间GPA的差异是多少?它是统计显著的吗?
(ii)从模型中去掉sat并重新估计这个方程。现在,作为运动员的估计影响是多大?讨论为什么这个估计值不同于第(ii)部分的结论。
(iv)在第(i)部分的模型中,容许作为运动员的影响会因性别不同而不同。检验如下原假设:在其他条件不变的情况下,女生是否是运动员没有差别。
(v)sat对colgpa的影响会因性别不同而不同吗?讲出你的根据。
第2题
文件CEOSAL2.RAW包含了177位首席执行官的数据,并可用来考察企业业绩对CEO薪水的影响。
(i)估计一个将年薪与企业销售量和市场价值相联系的模型。让这个模型对每个自变量的变化都具有常弹性。以方程的形式写出结论。
(ii)在第(i)部分的模型中增加profits。为什么这个变量不能以对数形式进入模型?你会说这些企业业绩变量解释了CEO薪水波动中的大部分吗?
(iii)在第(ii)部分的模型中增加ceoten。保持其他条件不变,延长一年CEO任期,估计的百分比回报是什么?
(iv)求出变量log(mktval)和prots之间的样本相关系数。这些变量高度相关吗?这对OLS估计量有什么影响?
第3题
(i) 估计一个将respond与resplast和avggift联系起来的线性概率模型。以通常的形式报告结果, 并解释变量resplast的系数。
(ii)过去捐助的平均水平看来会影响做出捐助响应的概率吗?
(iii) 在模型中增加变量propres p并解释其系数。(这里须注意, propresp增加1是最大可能变化。)
(iv) 在回归中增加propres p以后, resp last的系数有何变化?这讲得过去吗?
(v) 在模型中增加每年寄出邮件的数量mail year。它的估计影响有多大?为什么它不是邮件数量对响应的因果关系的一个较好的估计?
第4题
A.给出定解条件,一定能求出它的数值解
B.给出定解条件,一定能求出它的解析解
C.给出定解条件,有解时,一定能求出它的数值解
D.根据变量替换,一定能求出它的通解
第5题
本题利用NBASAL.RAW中的数据。
(i)估计一个线性回归模型,将单场得分与联赛中打球经历和位置(后卫、前锋或中锋)联系起来。包括打球经历的二次项形式,并将中锋作为基组。以通常的形式报告结果。
(ii)在第(i)部分中,你为什么不将所有三个位置虚拟变量包括进来?
(iii)保持经历不变,一个后卫的得分比一个中锋多吗?多多少?这个差异统计显著吗?
(iv)现在,将婚姻状况加入方程。保持位置和经历不变,已婚球员是否更高效(就单场得分来说)?
(v)加入婚姻状况和两个经历变量的交互项。在这个扩展的模型中,是否存在有力的证据表明婚姻状况影响单场得分?
(vi)使用单场助攻次数作为因变量估计(iv)中的模型。与(iv)的结果有明显的差异吗?请讨论。
第6题
利用PNTSPRD.RAW中的数据。
(i)变量favwin是一个二值变量,在拉斯维加斯所押的球队胜出了预定的分数差时取值1。估计所押球队获胜概率的线性概率模型为
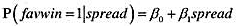
如果分数差包括了所有相关的信息,那我们预期β0=0.5。请解释。
(ii)用OLS估计第(i)部分的模型。相对于双侧备择假设检验H0:β0=0.5。同时使用通常的标准误和异方差一稳健的标准误。
(iii)spread在统计上显著吗?当spread=10时,被押球队获胜的估计概率是多少?
(iv)现在对P(favwin=Ilspread)估计一个概率单位模型。解释和检验截距项为0的虚拟假设。[提示:注意Φ(0)=0.5。]
(v)利用概率单位模型估计当spread=10时被押球队获胜的概率。并与第(iii)部分的LPM估计值相比较。
(vi)在概率单位模型中增加变量fuvhome、fav25和und25,并用似然比检验来检验这些变量的联合显著性。(x2分布中的自由度是多少?)解释这个结果,注意分数差是否包括了赛前可观测到的全部信息这个问题。
第7题
如下模型使得受教育回报还取决于父母双方受教育程度的总和pareduc:

如果某人父母总的教育年限为32年,那么他的教育回报比父母教育年限为24的人高百分之多少?这个差异在统计上显著吗?
(iii)如果在方程中将pareduc作为一个独立变量引入,则得到
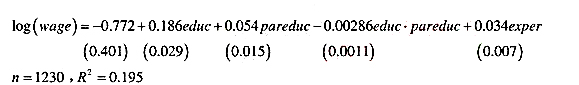
现在教育回报如何依赖于父母的受教育水平?找到双侧p值来检验原假设:教育回报取决于父母的受教育水平。你能得到什么结论?
第8题
利用BARIUM.RAW中的数据。
(i)用前119次观测(即不包含1988年的最后12个月观测),估计线性趋势模型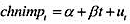 。这个回归的标准误是什么?
。这个回归的标准误是什么?
(ii)同样用除了最后12个月以外的所有数据,估计chnimp的一个AR(1)模型。把这个回归的标准误与第(i)部分中的标准误相比较。哪一个模型提供了更好的样本内拟合?
(iii)用第(i)和第(ii)部分中的模型计算1988年12个月的提前一期预测误差。(每个方法都应该得到12个预测误差。)计算并比较这两种方法的RMSE和MAE。就样本外提前一期预测而言,哪种方法效果更好?
(iv)在第(i)部分的回归中添加月度虚拟变量。它们是联合显著的吗?(当我们检验联合显著性时,不必担心误差中轻度的序列相关。)
第9题
考虑一个雇主根据工人是否参加工会的百分比及其他因素而提供养老金计划的线性概率模型:
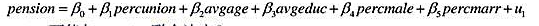
(i)为什么percunion可能与pension联合决定?
(ii)假设你可以对企业工人进行调查,并搜集工人家庭的信息。你能否想出可用于构造percunion的一个IV的信息。
(iii)你如何检验你所想到的变量是否为percunion的一个至少是合理的备选Ⅳ?
第10题
已知结构式模型为
式1:Y1=α0+α1Y2+α2X1+u1 式2:Y2=β0+β1Y1+β2X2+u2
其中,Y1和Y2是内生变量,X1和X2是外生变量。
(1)分析每一个结构方程的识别状况;(2)如果α2=0,各方程的识别状况会有什么变化?
第11题
SNMPv1是一个不安全的协议,管理站(Manager)与代理(Agent)之间通过(55)进行身份认证,由于认证信息没有加密,因此是不安全的。1998年公布的SNMPv3定义了基于用户的安全模型USM,其中的认证模型块结合(56)算法形成认证协议,产生了一个96位的报文摘要。SNMPv3还定义了基于视图的访问控制模型VACM。在这个模型中,用户被分成组,属于同一组的用户可以有不同的安全级别,其中,(57)具有最高安全级别。 RFC1757定义的RMON管理信息库是对MIB-2的扩充,其中的统计组记录(58)的管理信息,而矩阵组则记录(59)的通信情况。
A.团体名
B.用户名ID
C.访问权限
D.访问控制



















