阅读下列函数说明和C函数,将应填入(n)处的字句写在对应栏内。[说明]
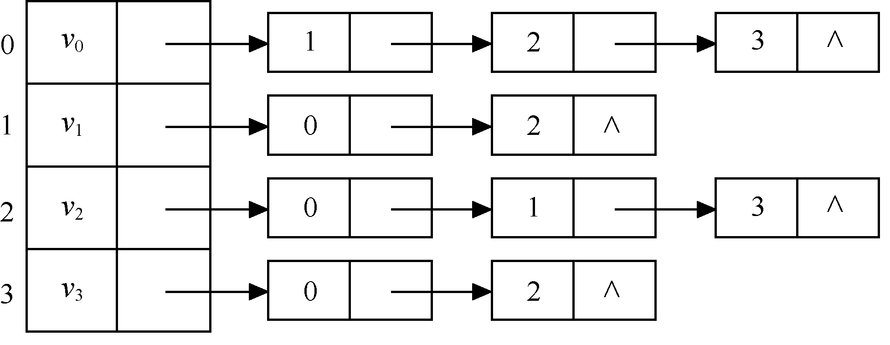
邻接表是图的一种顺序存储与链式存储结合的存储方法。其思想是:对于图G中的每个顶点 vi,将所有邻接于vi的顶点vj连成一个单链表,这个单链表就称为顶点vi的邻接表,其中表头称作顶点表结点VertexNode,其余结点称作边表结点EdgeNode。将所有的顶点表结点放到数组中,就构成了图的邻接表AdjList。邻接表表示的形式描述如下: define MaxVerNum 100 /*最大顶点数为100*/
typedef struct node{ /*边表结点*/
int adjvex; /*邻接点域*/
struct node *next; /*指向下一个边表结点的指针域*/ }EdgeNode;
typedef struct vnode{ /*顶点表结点*/
int vertex; /*顶点域*/
EdgeNode *firstedge; /*边表头指针*/
}VertexNode;
typedef VertexNode AdjList[MaxVerNum]; /*AdjList是邻接表类型*/
typedef struct{
AdjList adjlist; /*邻接表*/
int n; /*顶点数*/
}ALGraph; /*ALGraph是以邻接表方式存储的图类型*/
深度优先搜索遍历类似于树的先根遍历,是树的先根遍历的推广。
下面的函数利用递归算法,对以邻接表形式存储的图进行深度优先搜索:设初始状态是图中所有顶点未曾被访问,算法从某顶点v出发,访问此顶点,然后依次从v的邻接点出发进行搜索,直至所有与v相连的顶点都被访问;若图中尚有顶点未被访问,则选取这样的一个点作起始点,重复上述过程,直至对图的搜索完成。程序中的整型数组visited[]的作用是标记顶点i是否已被访问。
[函数]
void DFSTraverseAL(ALGraph *G)/*深度优先搜索以邻接表存储的图G*/
{ int i;
for(i=0;i<(1);i++) visited[i]=0;
for(i=0;i<(1);i++)if((2)) DFSAL(G,i);
}
void DFSAL(ALGraph *G,int i) /*从Vi出发对邻接表存储的图G进行搜索*/
{ EdgeNode *p;
(3);
p=(4);
while(p!=NULL) /*依次搜索Vi的邻接点Vj*/
{ if(! visited[(5)]) DFSAL(G,(5));
p=p->next; /*找Vi的下一个邻接点*/
}
}




 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
.jpg)
 答案
答案

.jpg)

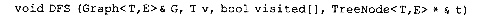 其中,指针t指向生成森林上具有图顶点v信息的根结点。(提示:在继续按深度方向从根v的某一未访问过的邻接顶点w向下遍历之前,建立子女结点。但需要判断是作为根的第一个子女还是作为其子女的右兄弟链入生成树)
其中,指针t指向生成森林上具有图顶点v信息的根结点。(提示:在继续按深度方向从根v的某一未访问过的邻接顶点w向下遍历之前,建立子女结点。但需要判断是作为根的第一个子女还是作为其子女的右兄弟链入生成树)